

 Hadoopとは、大容量のデータを効率よく処理するために分散処理技術を用いたオープンソースのフレームワークです。
Hadoopとは、大容量のデータを効率よく処理するために分散処理技術を用いたオープンソースのフレームワークです。
オープンソースなので低コストで導入することができ、多くの企業やシステムで導入されています。
本記事では、Hadoopとはなにか、特徴や仕組みについて詳しく解説します。
\ 2週間無料でお試しできます! /
 Unix/Linux系VPSをこの価格で!
Unix/Linux系VPSをこの価格で!
・全プランSSD搭載でコストパフォーマンス◎
・豊富なOSラインアップ
・充実の無料サポート
VPSを使ってみる
目次
Hadoopとは
Hadoopの概要
Hadoopは、大規模データの分散処理を可能にするオープンソースのフレームワークです。
Apache Software Foundationが開発・管理しています。
Hadoopは、分散ファイルシステム(HDFS)や並列処理フレームワーク(MapReduce)などのコンポーネントを利用し、複数のサーバーにデータを分散させて並列処理を行います。
これにより、大容量データでも効率的かつ高速に処理を行うことができ、多くのビッグデータを利用したシステムの基盤として導入されています。
Hadoopの背景
Hadoopの起源は、2000年代初頭の検索エンジン開発にさかのぼります。
当時、大量のインターネット上の膨大な文書を効率的に収集し、検索結果を表示するためには、インデックスを作成する必要がありました。
この「文書を効率的に収集し、インデックスを作成する」という一連の作業を効率よく行うための方法として、複数のコンピューターで並行処理する手法(分散処理技術)が考案されました。
この手法をもとに、Hadoopが2008年にオープンソースとして公開されました。
さらに2010年頃から、大容量データを活用する需要が高まり、その中でHadoopが注目され始めます。
Hadoopはビッグデータ処理基盤として活用されるようになりました。
Hadoopの仕組み
HDFS
Hadoopは、複数のコンポーネントが連携して動作する分散システムです。
その中でも、HDFS(Hadoop Distributed File System)は、Hadoopの中核を成す分散ファイルシステムです。
HDFSは、大規模データを複数のノードに分散して保存することで、高い耐障害性と処理効率を実現します。
HDFSの仕組み
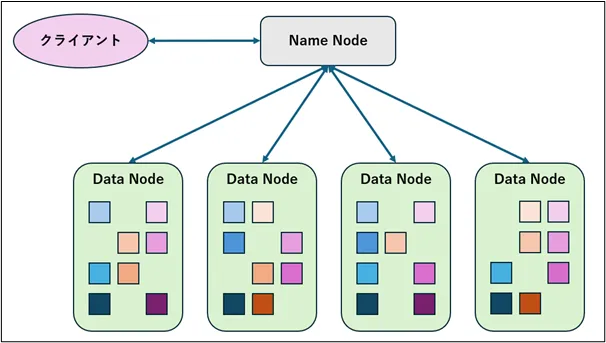
HDFSは、NameNodeとDataNodeという2種類のノードで構成されています。
・NameNode
ファイルシステムのメタデータを管理し、クライアントからのリクエストを処理します。
・DataNode
実際のデータブロックを保存し、読み書き操作を行います。
データは通常64MBまたは128MBのブロックに分割され、複数のDataNodeに複製して保存されます。
この仕組みにより、複数のDataNodeが並列でデータの読み書きが行えるだけでなく、万が一DataNodeに障害が発生しても、データの可用性が保たれます。
MapReduce
MapReduceは、大規模データセットを並列で処理するために設計されています。
MapReduceの構成
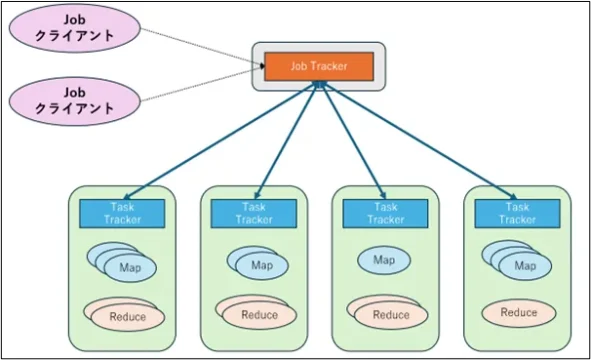
Jobクライアントからジョブの依頼を受けたJob Trackerが、各ノードのTaskTrackerに対してタスクの割り当て、スケジュールを行います。
TaskTrackerでは、「Map」と「Reduce」の2つの段階で処理を分割し、各プロセスの実行および管理を行います。
MapReduceの処理の流れ
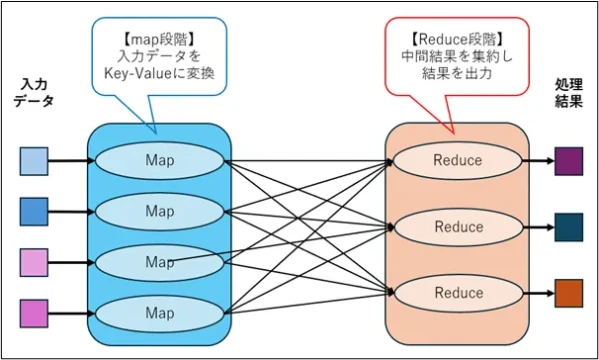
Map段階では、入力データを key-value ペアに変換し、中間結果を生成します。
Reduce段階では、Map段階で生成された中間結果を集約して最終的な出力を生成します。
この単純な処理モデルにより、開発者は複雑な分散システムの詳細を意識することなく、大規模データ処理アプリケーションを実装できます。
MapReduceジョブは自動的にクラスター内の複数のノードに分散され、並列で実行されます。
YARN
YARN(Yet Another Resource Negotiator)は、Hadoopクラスター全体のリソース管理とジョブスケジューリングを担当するコンポーネントです。
Hadoop 2.0で導入され、MapReduceに依存しない汎用的なリソース管理システムとして機能します。
YARNの仕組み
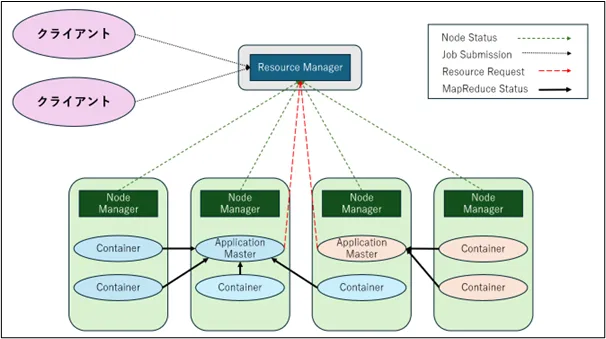
・ResourceManager:クラスター全体のリソースを管理
・NodeManager:各処理ノードを管理
・Application Master:リソース状況を確認し、Container確保をResourceManagerに要求
・Container:処理を実行する
YARNの導入により、MapReduce以外の処理エンジン(SparkやFlink等)もHadoopクラスター上で効率的に実行できるようになりました。
これにより、Hadoopエコシステムの柔軟性と拡張性が大幅に向上し、様々な種類のデータ処理ワークロードに対応できるようになりました。
\ 2週間無料でお試しできます! /
VPSを使ってみる
Hadoopの特徴
高いスケーラビリティ
Hadoopの最大の特徴の一つは、その優れたスケーラビリティです。
HDFSを利用することで、データを複数のノードに分散して保存するだけでなく、必要に応じて簡単にノードを追加できます。
この仕組みにより、ペタバイト級の大規模データにも柔軟に対応可能です。
さらに、データ処理能力も同様にスケールアップが可能です。
MapReduceを活用することで、タスクを複数のノードに分散し、並列処理を実現します。
処理するデータ量が増加しても、ノードを追加するだけで処理能力を向上させることができ、効率的に対応できます。
多様なデータを格納可能
Hadoopのもう一つの大きな特徴は、多様なデータ形式を柔軟に扱える点です。
従来のRDB(リレーショナルデータベース)では、事前に厳密なスキーマ定義が必要でしたが、Hadoopではデータを格納する際にスキーマ定義が不要です。
さらに、HDFSを利用することで、構造化データだけでなく、XMLファイルなどの半構造化データや、画像、動画、音声ファイルといった非構造化データも格納することが可能です。
この柔軟性により、企業はさまざまなデータを一元管理し、効率的に分析できます。
また、後からデータを取り出す際には、必要に応じて解析し、任意のスキーマに適合させることが可能です。
そのため、同じデータを異なる視点から分析することも容易です。
処理が高速
Hadoopは、分散処理と並列計算によって高速な処理能力を実現しており、ビッグデータ分析における大きな強みとなっています。
従来のシステムでは、データを順次処理するため、データ量が増加するほど処理時間が長くなるという課題がありました。
しかし、Hadoopでは、MapReduceを活用してクエリをタスクに分割し、複数のノードで同時に処理を行うことで、この課題を克服しています。
さらに、HDFSがデータを複数のノードに分散して保存しているため、データの読み書きも高速化されています。
これにより、複雑なクエリでも従来のシステムに比べて大幅に高速に実行できます。
企業はHadoopを活用することで、リアルタイムに近いデータ分析を実現し、迅速な意思決定を行うことが可能です。
耐障害性の実現
Hadoopの重要な特徴の一つに、高いフォールトトレランス(耐障害性)が挙げられます。
大規模なクラスターシステムでは、ハードウェアの故障は避けられない問題です。
Hadoopでは、HDFSを用いてデータを複数のノードに複製して保存することで、この問題に対応しています。
さらに、Hadoop 2.0以降では、NameNodeの冗長化が可能となり、単一障害点(SPOF)の問題も解決されました。
これにより、一部のノードが故障しても、他のノードに保存されたデータのコピーを使用して処理を継続できます。
また、MapReduce処理においても、タスクを実行中のノードが故障した場合、自動的に他のノードにタスクが再度割り当てられ、データ損失のリスクを最小限に抑えつつ、高い可用性を確保しています。
Hadoopは、24時間365日の連続運用が求められる企業システムにおいても、高い信頼性を提供する仕組みを備えています。
低コストで利用可能
Hadoopの大きな魅力の一つは、低コストで利用できる点です。
具体的には、以下の特徴が挙げられます
・オープンソースソフトウェアであるため、ライセンス料が不要
・汎用的な機器で動作するため、高価な専用機器が不要
・必要に応じて段階的にシステムを拡張可能
・自動的なデータ複製や障害時の自動復旧機能により、管理コストを低減
これらの理由から、Hadoopは初期導入コストを最小限に抑えつつ、ビジネスの成長に応じて柔軟にシステムを拡張できます。
その結果、Hadoopは中小企業から大企業まで、幅広い規模の組織がビッグデータ分析を低コストで実現するための強力なツールとなっています。
\ 2週間無料でお試しできます! /
VPSを使ってみる
まとめ
本記事では、Hadoopの仕組みや特徴について解説しました。
Hadoopは、大容量のデータを効率的に処理・分析するためのオープンソースフレームワークです。
HDFSやMapReduceといった仕組みにより、分散処理や並列処理を可能にし、高いスケーラビリティと耐障害性を実現しています。
さらに、オープンソースソフトウェアであり、汎用的な機器で動作するため、初期導入コストを最小限に抑えながら、ビジネスニーズに応じて柔軟にシステムを拡張できます。
そのため、Hadoopはビッグデータのシステム基盤として、多くの企業で導入・活用されています。
LinuxのVPSならミライサーバー
ミライサーバーは、アシストアップ株式会社が提供している、Unix系サーバーに特化したホスティングサービスです。
ミライサーバーのVPSでは、高速処理が可能なSSDを全プランに搭載しています。
OSは、UbuntuやDebian、AlmaLinuxなどの豊富なラインアップから選択することができます。
2週間無料トライアルを実施しておりますので、まずはお気軽にお試しください。

プランの選択でお困りの場合は、ぜひ一度お問い合わせください。

2023.08.03
VPSに申込み、SSH接続するまでの流れ【ミライサーバー】
オンラインビジネスやWebサイトの運営を始める際には、ホスティングサービスの中から自分の用途に合ったサーバー環境を利用することが一般的です。...

